How to Create a Data Route from a Kafka Topic to an SQL Database in 15 Minutes? ⏲️
Hint: it involves using Apache Camel.
Suppose we have a Kafka topic receiving records in JSON format. We want to insert these records into an SQL database in real-time. A very common use case!
Apache Camel is essentially an open-source framework for coding and running data exchange pipelines between applications. It’s mature, has a large community, and has been around for over 15 years.
There are several ways to use Camel, but here I’ll present the Java DSL.
👉 I start by selecting the Maven archetype based on how I will deploy my route (more details on deployment in my post scheduled for Saturday), so I’m not starting from scratch: I have a project template already made, I just have to code.
📦 Next, I go to the mvn repository to get the dependencies I need, namely Kafka, a JDBC driver, and Jackson for processing JSON.
And now let’s build the route.
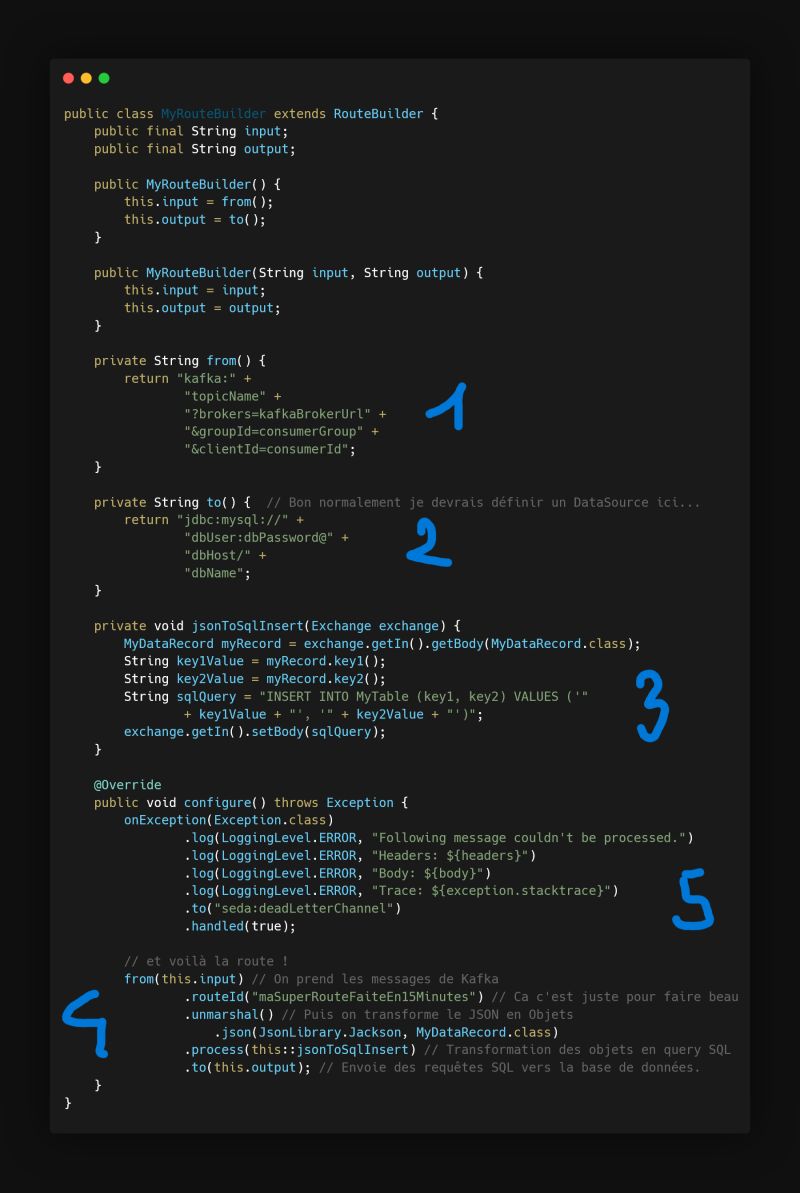
1️⃣ We take data from Kafka, so I write a small function that returns the URI to this Kafka, and specifically the topic from which I must consume.
2️⃣ We push data into an SQL database, so I also write a small function that returns the URI to this database.
3️⃣ In between, I will need to transform the data retrieved from the topic into an SQL query, so I use a “processor” that transforms each message coming from the topic into an INSERT query.
Note that for this example, I’ve hard-coded many values, but obviously all configuration values should normally go in an application.properties file and be injected at runtime!
4️⃣ Then I write my route: from()… to()… And yes, that’s Camel’s DSL, we simply describe the route!
5️⃣ To finish, I need to handle errors. In my case, let’s keep it simple: I log and push all messages that generated any exception into a dead letter channel (if you’re not familiar with this pattern, let me know in the comments, and I’ll publish about it) so they can be reviewed later.
And there we have it, a working pipeline in 15 minutes. I could have added filters, parallelized the processing in just a few lines, that’s the great strength of Camel.
Why didn’t I directly put the URIs in the from() and to() of the route? Good question, it’s for better testing!
How to test the route.
Actually, it’s better to start with a test than with the route.
Because who would dare to launch a pipeline they’ve developed directly in a live environment?
Even on staging or pre-prod machines, don’t do this! 🛑
Of course, there’s a high chance that you’ll blow up your databases/message brokers, but more simply: if there’s any error, all the time you spent deploying your pipeline is wasted. Yes: you’ll need to make corrections, go back to your workstation, fix, redeploy, test… 😭🔫
So, how do I test the route made with Apache Camel yesterday?
Well, it’s quite easy, since Camel also provides a testing framework.
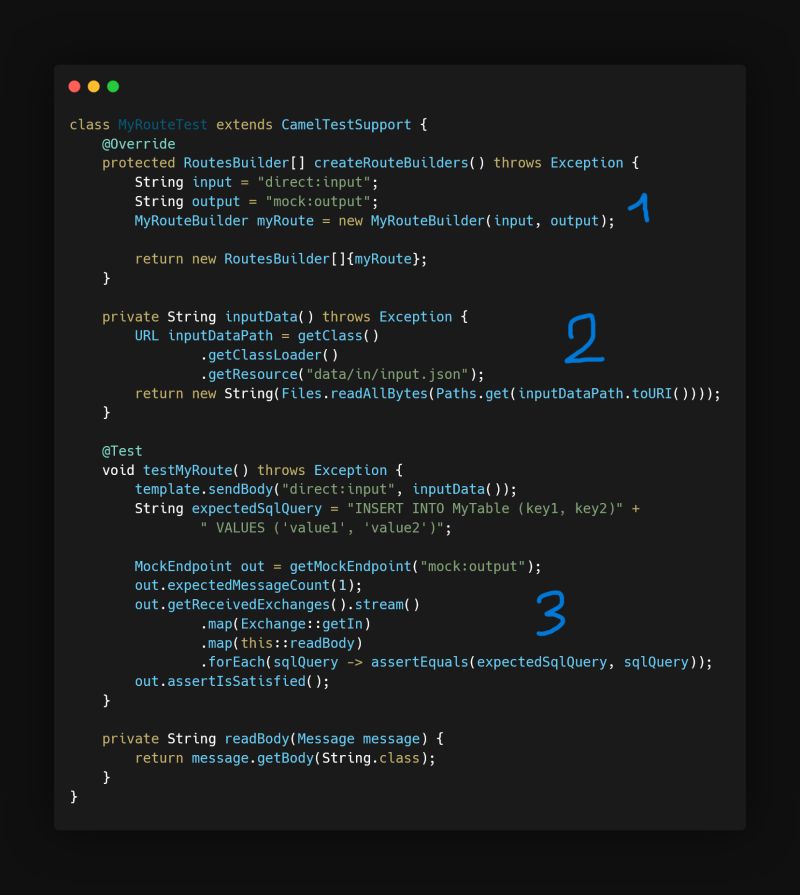
This allows me to:
1️⃣ Instantiate my route, taking care to change the input and output and to use “fakes”.
2️⃣ Load a test message.
3️⃣ Verify that the message(s) I get in the output correspond to what I put in for testing.
But beware, this isn’t the end: here, I’m only testing the nominal case for the sake of brevity. There are many other cases to test:
- Cases where the input data is not in the correct format
- Cases where the input data is not the right size
- Cases where the input data is not named correctly (wrong key in the JSON, for example) …
And voilà, I can launch my route locally, observe its behavior, see if my dependencies are properly set up, and check that everything works!
How to simply run the pipeline and the different ways to deploy it.
When I’m done testing and developing the pipeline, it is time to deploy it.
For deploying the pipeline, there are plenty of options available to us, depending on the context:
👉 Do you have an infrastructure running on Kubernetes? Great, with Camel K, you can deploy rapidly to a cluster in just one command!
👉 Do you have an existing Spring ecosystem? Awesome, with Camel Spring Boot, you can integrate routes within a Spring context.
👉 Do you have Karaf servers? Good news, with Camel Karaf, you can create OSGi-compatible routes.
👉 Do you have an application container server like Tomcat? Great, we can build a .war and run Camel inside it!
👉 Do you have a simple server with a JVM? Okay, we can create a fat-jar and run it on that!
Whether you use Kube or not, with Camel Quarkus, you can run all of this in Quarkus, making the footprint (RAM, CPU, load time) of your pipeline microscopic.
This concludes this article. Data pipelining should not be complex, and it is not when we use the right tools.