Situation: The pipeline is in production, it’s running. But since yesterday, some data isn’t passing through, and error logs are showing up, or worse, the errors aren’t handled and the entire pipeline has crashed!
This is a classic scenario for a data engineer, and it’s time to dive into the code and data to figure out what’s going on.
I’m going to show you a generic method, based on several years of experience in fixing, rectifying, and improving data pipelines.
Step 1: Find the problem data
Before diving into the code, the first step is to identify which data points are causing errors. Keep these data handy. For example, if they are in JSON, save them in a file.
Step 2: Dig into the code
Next, dive into the code and pinpoint the problematic instruction. I’ve illustrated a data extraction function: for an identifier, two records are pulled from two different databases and then merged.
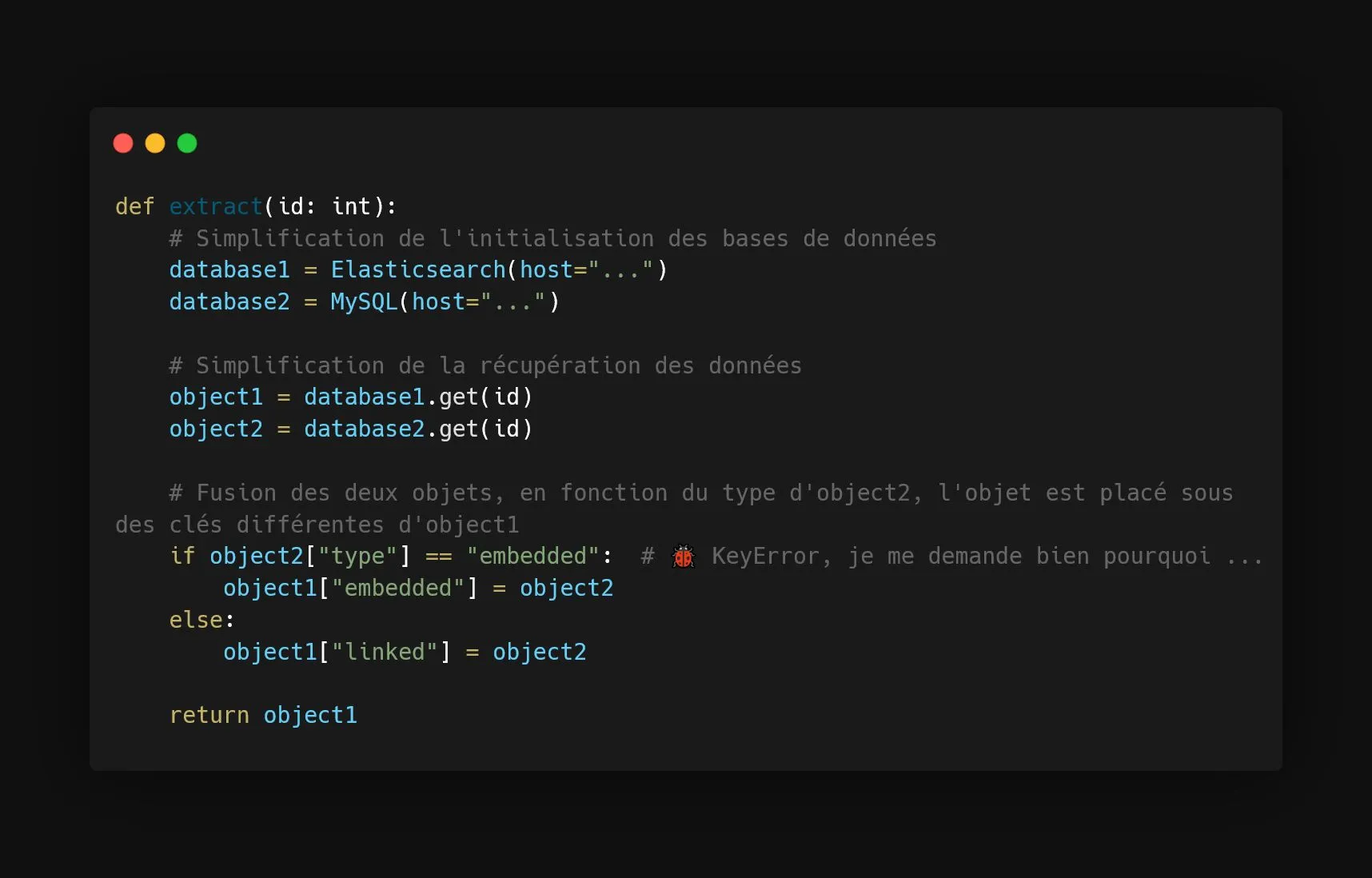
Can you immediately see the problem? Well, in this example, the problem is quite obvious, but most of the time it’s not so apparent!
The best way to see the problem concretely is to execute the code locally. But surprise: it’s going to be complicated to execute anything since the function calls external databases. I can’t run it locally on my PC to reproduce the problem with the troublesome data. Unless I have local access to production databases and execute the function on them, but if that idea doesn’t bother you, I suggest you consider reorienting towards gardening with round-tipped shears 👨🌾
The problem is that this function mixes multiple responsibilities: taking the data and then merging it.
So, we’re going to separate these responsibilities into two different functions:
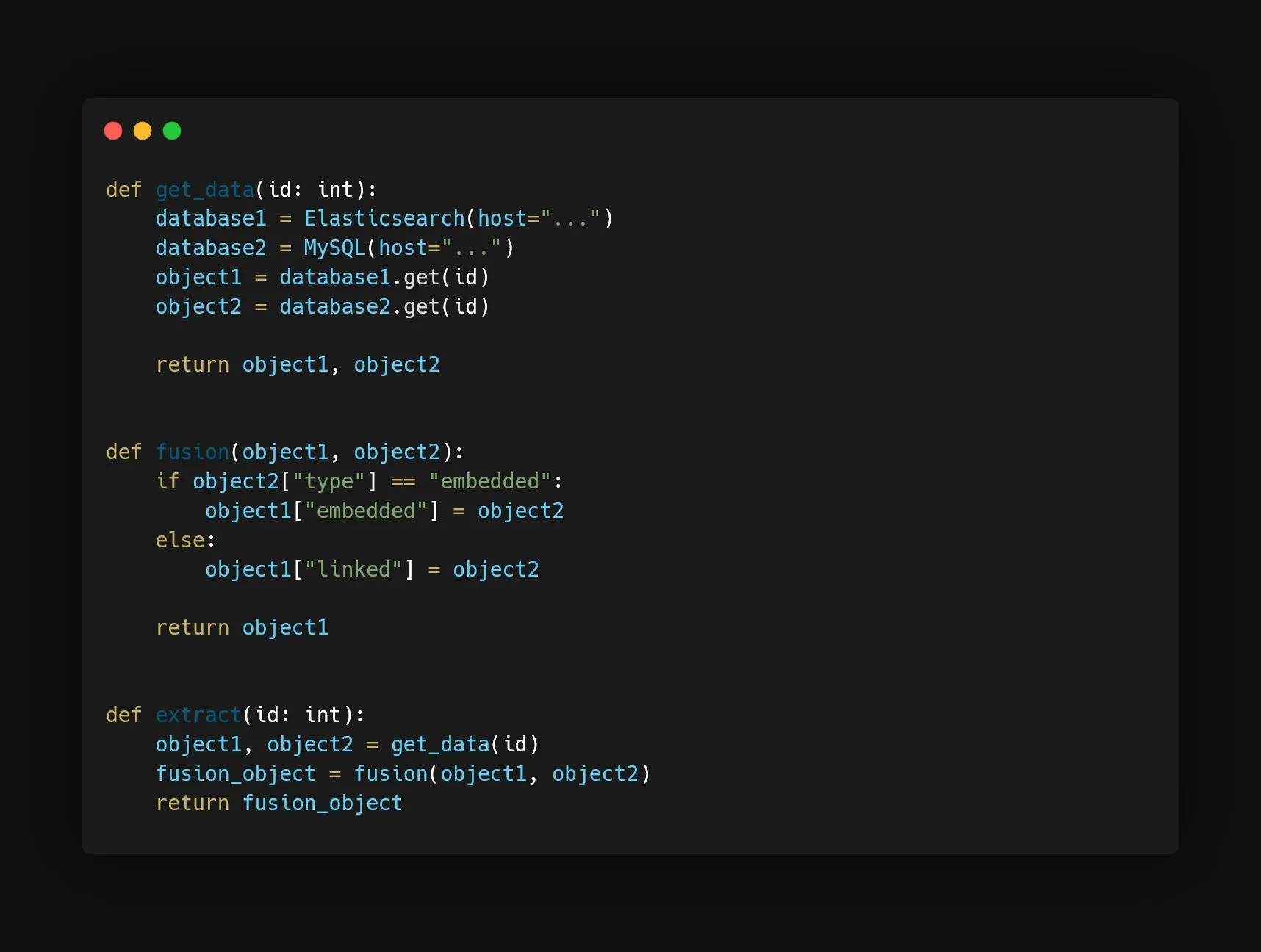
Having separated this function into two, we applied the Single-responsibility principle. Of course in this post’s example it is a very lightweight version of it. In reality, you want to keep separated into different modules the things that change for different reasons. Here, the database access and merging the data are two different things because the access to the database can change without the need of changing the merging logic, and vice versa.
Step 3: Refactor and test
Thanks to this little refactoring, we can write a test for our merging function (See image below). The input data for this test are the “problematic” data isolated earlier, in step 1.
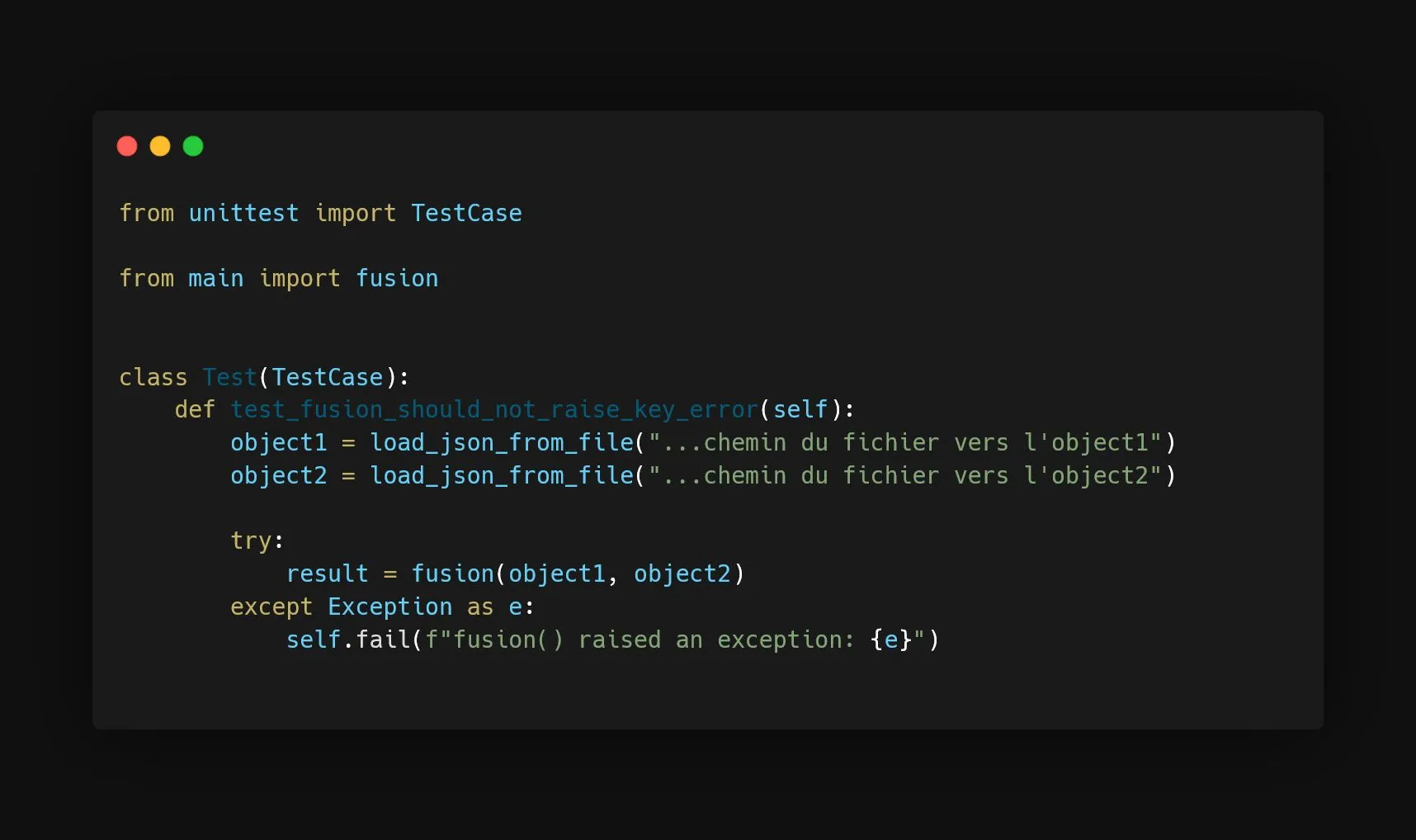
Thus, I can execute the merging function locally by running the unit test, debug the problem using breakpoints if necessary, and finally correct it.
In my example, the problem is that if the key "type" doesn’t exist on object2, the execution of object2["type"] will throw a KeyError, interrupting the function.
Step 4: Keep the changes and the test
We keep the change and the test in the code! This way, after your intervention, the codebase will be even more robust, and the responsibilities will be decoupled.
Simple as that. Fix the root issue, clean up the code, and leave things better than you found them.