How do LLMs run locally on an AMD AI Max 395+?
Last Thursday I talked about my new PC: a Framework Desktop with an AMD AI Max 395+ and 128 GB of LPDDR5. AMD pitches this APU as the heart of an “AI PC”: a consumer machine that can do local AI without a dedicated GPU.
On paper, that sounds great. In practice: what can you actually run, and how fast?
To find out, I benchmarked a wide range of models locally. Here’s what I saw.
Setup and protocol
Benchmark command
To compare models on a stable basis:
llama-bench -p 512 -n 128 -t 6 -ngl 999pp(tk/s) = prefill: prompt/context ingestion speed.tg(tk/s) = decode: generation speed you feel in chat.
Parameters:
p=512: fixed prompt to measure prefill.n=128: enough generation to stabilize the metric.t=6: 6 CPU threads.ngl=999: max GPU offload.
Backend and hardware
Tests via llama.cpp in Vulkan on the iGPU (UMA):
- iGPU: Radeon 8060S Graphics (RDNA, Vulkan)
- UMA: shared CPU/GPU memory
- acceleration via KHR cooperative matrices
Important: no dedicated GPU, so bandwidth and UMA latency are the bottlenecks.
Results
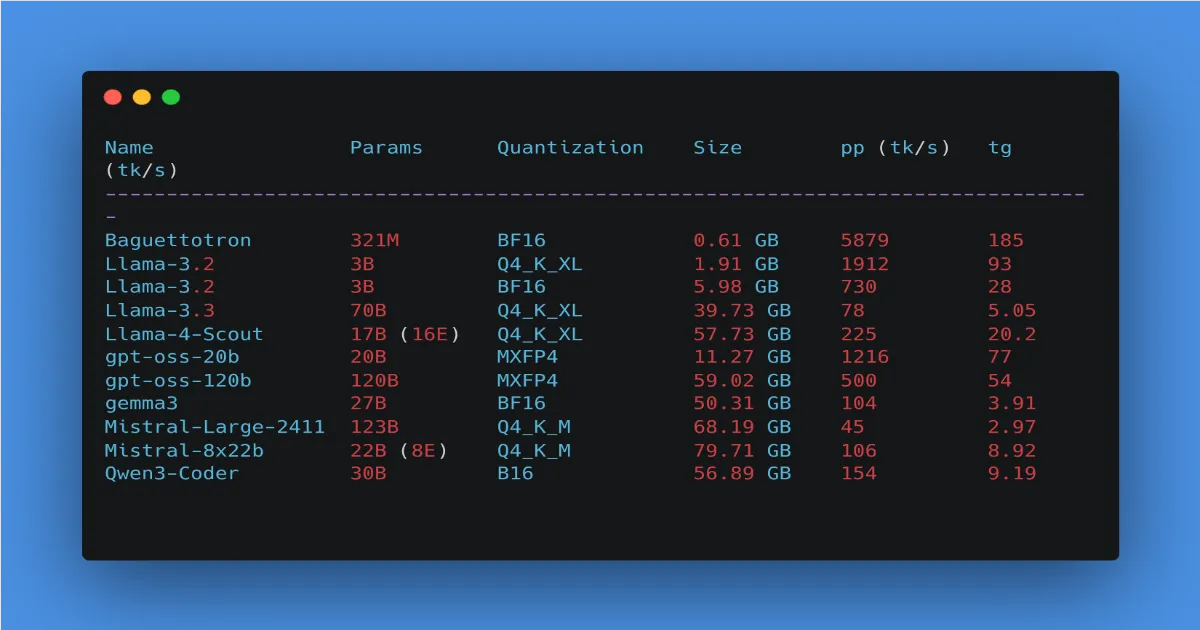
Raw table
| Name | Params | Quantization | Size | Prefill (tk/s) | Decode (tk/s) |
|---|---|---|---|---|---|
| Baguettotron | 321M | BF16 | 612 MB | 5879 | 185 |
| Llama-3.2 | 3B | Q4_K_XL | 1.91 GB | 1912 | 93 |
| Llama-3.2 | 3B | BF16 | 5.98 GB | 730 | 28 |
| Llama-3.3 | 70B | Q4_K_XL | 39.73 GB | 78 | 5.05 |
| Llama-4-Scout | 17B (16E) | Q4_K_XL | 57.73 GB | 225 | 20.2 |
| gpt-oss-20b | 20B | MXFP4 | 11.27 GB | 1216 | 77 |
| gpt-oss-120b | 120B | MXFP4 | 59.02 GB | 500 | 54 |
| gemma3 | 27B | BF16 | 50.31 GB | 104 | 3.91 |
| Mistral-Large-2411 | 123B | Q4_K_M | 68.19 GB | 45 | 2.97 |
| Mistral-8x22b | 22B (8E) | Q4_K_M | 79.71 GB | 106 | 8.92 |
| Qwen3-Coder | 30B | BF16 | 56.89 GB | 154 | 9.19 |
Key takeaways without drowning in details
- Small models (<=3B) are ultra smooth: huge prefill, very high decode.
- Quantization is a straight performance multiplier: a 3B in Q4 jumps from ~28 to ~93 tk/s in decode, prefill x2-3. On UMA, fewer bits = more throughput.
- Between ~10B and ~30B is the “useful but variable” zone: some 20-30B stay pleasant (about 9-20 tk/s), others drop to 4 tk/s. Architecture + kernels + quant > raw params.
- Large dense models (70B+) run but slowly: decode in the 3-5 tk/s range, usable if you are patient.
- MoE and exotic quantizations break the rules: MXFP4 (GPT-OSS) delivers perf unrelated to size. Weight/params -> perf is not monotonic.
Conclusion: AI PC, myth or reality?
Yes, you can run AI models locally
Unsurprising: small and mid-size quantized models run great. For chat, code, simple RAG, (very) light agents: okay.
Yes, you can load models other rigs can’t
The UMA + 128 GB combo lets you load 60-80 GB monsters. Some MoE or extreme quantization models fit here while they fail on typical “gaming” builds. On memory capacity, this APU impresses.
But, you don’t run the current flagships
The latest Gemini, Claude Opus 4.5, or GPT-5.1 are in another league. Even if local variants arrive, today’s flagships are too big and/or too compute hungry for this APU.
And the performance gap is huge:
You can load “big” thanks to RAM, but on deep dense models decode collapses to a few tokens per second, while a real dedicated GPU delivers tens or hundreds.
Bottom line: local AI on this class of APU is great for small and mid models, but it is nowhere near flagship performance. If you want true top-tier LLM speed or quality today, you still need dedicated hardware, or the cloud. Local AI at parity with the best models is not here yet.